Case Study
Introduction
Otto is an open-source, web-based, automated ETL workflow manager that orchestrates the gathering, transforming, and loading of data at scheduled intervals. Otto emphasizes ease of use for JavaScript developers and clear observability into their data processing: errors or bottlenecks their workflow is running into, why they happened, and the details they need to fix them.
Problem Domain
Workflows
A workflow is a series of tasks executed in sequence from the beginning to the end of a working process.
“Workflow” is a broad term, and workflows look different across different industries. Consider a hypothetical pharmaceutical company, Pharma Co. To decide which drug manufacturers to work with, Pharma Co. must work extensively with multiple sources of data. The FDA gathers data about manufacturers, such as inspections and complaints, and Pharma Co. collects and combines this data to add to its own database for later analysis. Initially, Pharma Co. did this manually. A developer would query numerous FDA database endpoints for information on citations and inspections of drug manufacturing facilities. The developer would send this information to clerical staff, who would clean the data and add it to Pharma Co’s internal database. Analysts would then use this data to determine which manufacturers best fit Pharma Co’s needs.
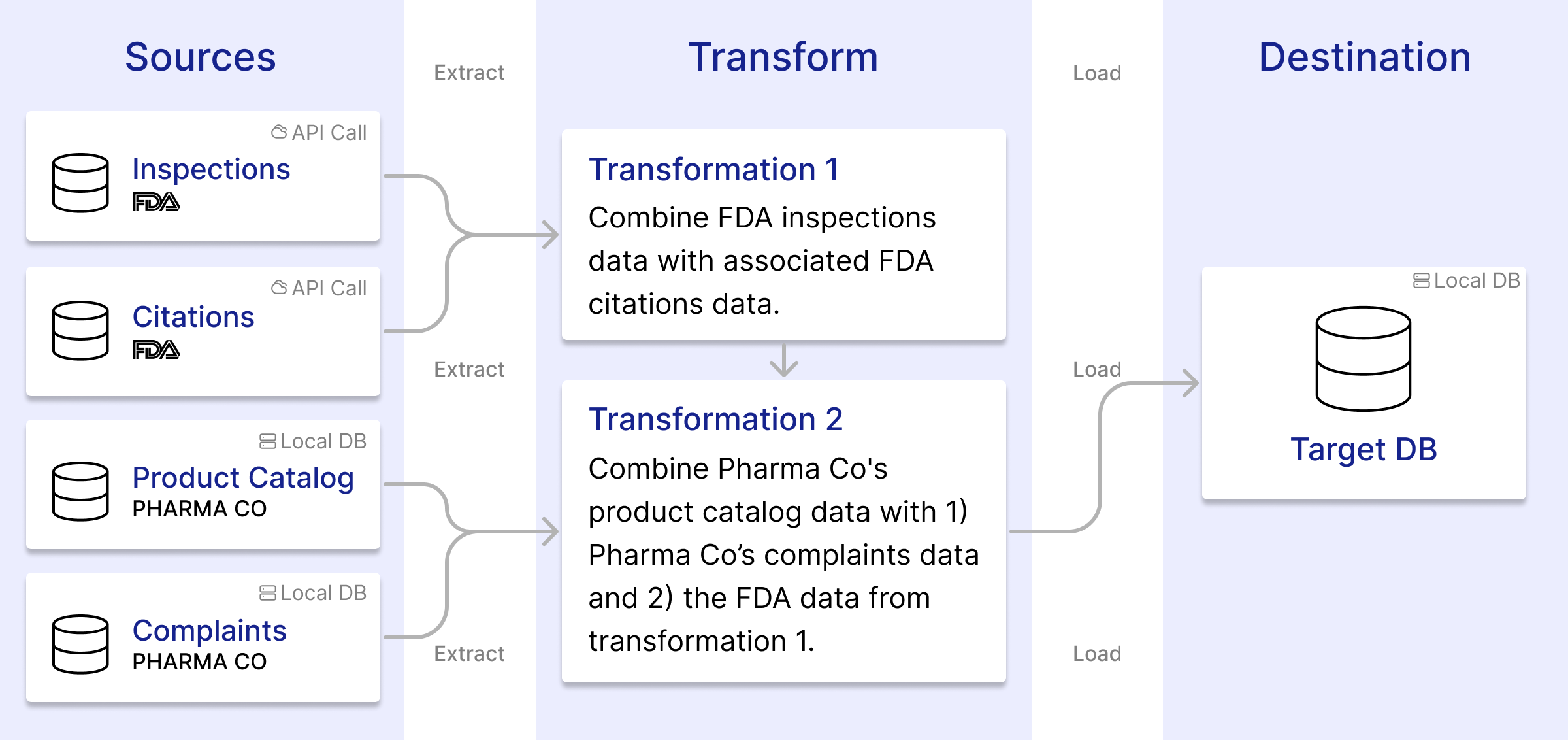
Workflow Automation
Workflow automation tools remove the need to manually transfer and manipulate information. Developers can use these tools to create data pipelines that perform those tasks, such as querying APIs, posting to social media, or sending emails, automatically.
The process by which workflow automation tools perform these tasks is called workflow orchestration. Workflow orchestration is the act of scheduling, executing, and monitoring tasks in a workflow to achieve a specific business objective. A workflow orchestration engine must ensure that these tasks are executed in sequence and that the correct actions are taken at each step in the workflow.
Each individual task in a workflow, such as making an API call and receiving response data, is encapsulated into a unit called a node. Workflows may contain several kinds of nodes, each with a different associated action. Scheduling nodes initiate cron jobs that execute a workflow at specified times. Extract nodes query APIs or databases for resources. Transform nodes execute user-provided code to modify incoming data and return the result of the transformation. Finally, load nodes send data to an external destination, usually a database.
A workflow orchestration system must handle the flow of data throughout these nodes. Transform and load nodes require the output data of the previous node(s) in the workflow. The system must also stop the process and return a comprehensible error message if one of the above node executions fails.
Ideally, a workflow automation tool will also log past executions of the workflow and maintain metrics data on those past executions. When users can view the data that flowed through past executions of the workflow, they can better diagnose errors that may have occurred during the data transformation process. Metrics also help the user identify where common errors are happening and what bottlenecks exist in the workflow.
ETL
Extract, transform, and load (ETL) is a data pipeline process of combining data from multiple sources into a central repository. ETL solves the problem of data scattered across disparate locations, such as various databases, files, and tools. Without some way of managing that data, teams may struggle to access up-to-date information, and analysts may not have all the data they need to answer their complex questions. Business managers cannot rely on reporting to be done on a consistent schedule, and business analysts lack visibility into their organization. Finally, software engineers must continually handle other departments’ requests for data, leaving them less time for more complex, impactful work.
Pharma Co.’s process is a perfect example of an ETL workflow. Let’s examine what that means.
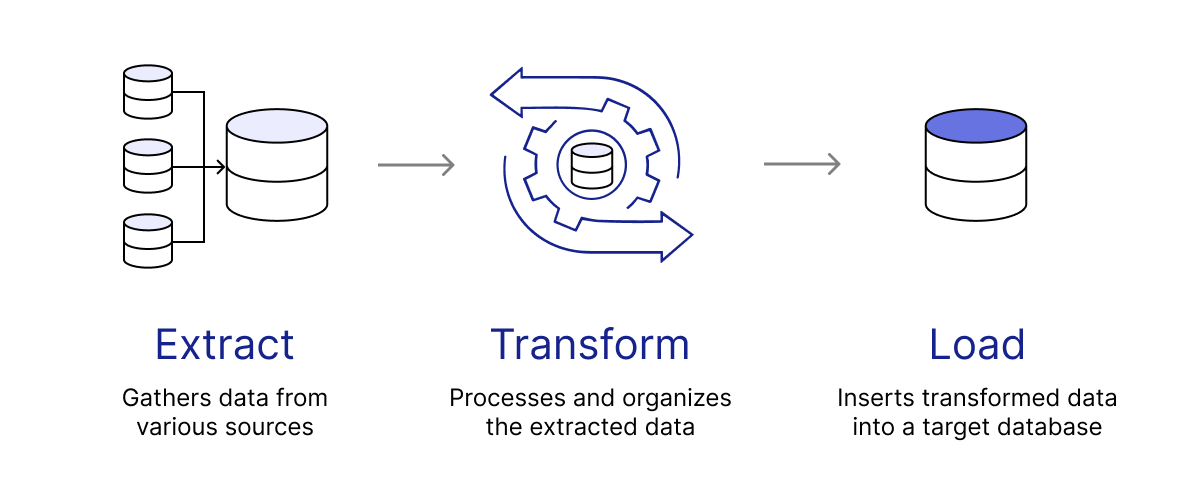
There are three high-level steps to ETL: data extraction, data transformation, and data loading.
- Data extraction: Handles the retrieval of data from diverse sources such as databases, APIs, files, or web services. Developers often extract from several of these sources in a single workflow.
- Data transformation: Converts the extracted data into a consistent format that is compatible with the destination system. Data transformation may include tasks such as data cleansing, validation, normalization, aggregation, and enrichment (i.e, adding new data). Often, several of these transformations take place in sequence.
- Data loading: Loads the transformed data into a database. A validation step may optionally ensure that the load operation was successful and accurate.
ETL can be further subdivided into modern ETL and light ETL. The main differences between modern ETL and light ETL are the volume of data extracted, the complexity of the data transformations and the size of the workflows.
Modern ETL workflows orchestrate a great variety of individual tasks, and can handle up to terabytes, petabytes or even exabytes of data. Light ETL workflows, however, have fewer sources and handle less data–perhaps megabytes or a few gigabytes.
Modern ETL workflows may also involve multiple steps and complex transformation operations such as data cleansing, validation, enrichment, and consolidation. Light ETL workflows contain far fewer steps than traditional workflows and perform simpler transformations, including data-type conversions, filtering, sorting, and joining.
Modern ETL is better suited for enterprises with large workflows, while light ETL is best suited to small- or medium-sized companies and/or smaller workflows. Though Pharma Co. is a large company, here it does not need to transfer or store large amounts of data, so a light-ETL tool best meets their needs.
Let’s return to Pharma Co. Their existing workflow could benefit from an ETL pipeline workflow automation system. While they could create one from scratch, their development team does not have the resources to build an orchestration engine as described above. Instead, they decide to explore the many workflow automation tools that already exist. These existing tools fall upon a spectrum, from lower-code solutions suitable for laypeople to solutions requiring professional programming skills.
Existing Solutions
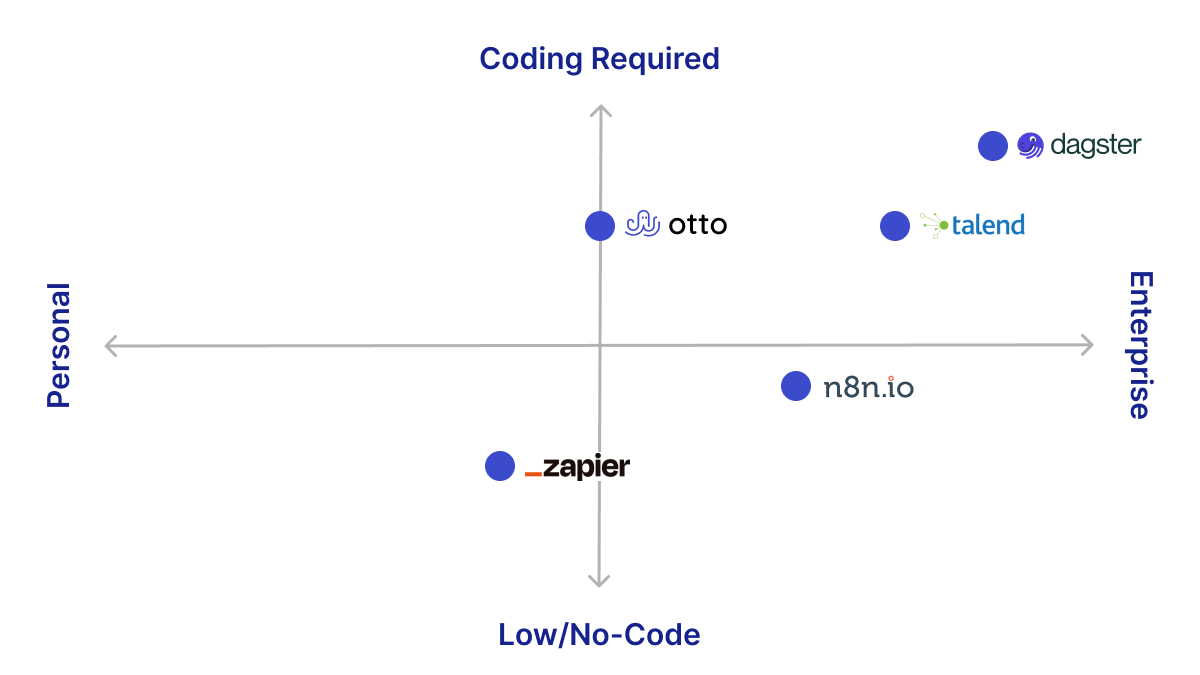
“No-code” tools, such as IFTTT and Zapier, prioritize ease of use and approachability for non-programmers. They have approachable UIs and templates that abstract away the technical details of automation, including pre-built integrations with applications like PostgreSQL or Salesforce to make it simpler to retrieve, process, or load those applications’ data. However, these tools do not allow users much flexibility to manipulate this data, create a more nuanced control flow, or write custom code.
At the other end of the spectrum, code-based tools like Windmill and Dagster allow software engineers to use their local IDE to write data-processing code. They offer significant flexibility in dealing with complex use cases and customization of functionality like HTTP request retries–i.e., resending any HTTP requests that have returned in failure after increasing intervals to overcome temporary network failure. However, these tools are more difficult to set up and configure and require much more technical skill than low-code options.
In between are several tools that balance ease of use and flexibility. Like “no-code” solutions, they usually offer pre-built integrations with other applications and UIs that are more approachable for non-technical users, while also giving users some flexibility to manipulate data through code snippets and to create more complex workflows. Included in this middle ground are tools such as n8n 2, Retool 3, and Talend 4 .
Members of this final group of tools are known for the many use cases and integrations that they offer. N8n, for instance, offers integrations with social media and messaging apps like Facebook and Slack. Users are able to send messages to distinct chat groups or make posts on these services using n8n. Users can also send emails on Gmail, set up events on Google Calendar, modify playlists on Spotify, and perform many other tasks as a part of their workflows. N8n also offers a variety of ways to initiate their workflows. To name a few, a user can schedule their workflows’ executions, set them to execute upon receiving a http request via webhook, or through a manual user click. When a workflow fails, n8n provides insight into the cause of failure through displaying errors in the nodes that failed and the logging of previous executions of a workflow.
While tools like n8n offer a great deal of flexibility, many of their features just act as clutter to a user who is there only to create an ETL pipeline. Integrations with apps like Facebook and Google Calendar are unnecessary when building ETL data pipelines. Even certain options for starting a workflow, such as via webhook http request, are unnecessary for most ETL data pipeline use. And while they provide logging and error notification, they do not provide metrics to quickly ascertain the recent performance of a given workflow.
There are a few existing workflow-automation tools designed specifically for ETL pipelines. One such option is Talend’s Pipeline Designer tool. Talend’s pipeline designer tool allows users to specify what data source to extract data from, transform the data in some arbitrary way, then load the finalized data to a data source of your choice. Data can be transformed using Talend’s graphical user interface, but if users want to transform the data in a way that is not covered by Talend’s existing options, the tool also allows them to write custom code to do so in either Python or Data Shaping Query Language, a derivative of SQL.
Though Talend offers a dedicated space to create ETL data pipelines, it still has a number of drawbacks. Talend Pipeline Designer makes it unclear how to execute the created workflow except manually. Additionally, more complex transformations can only be done through Python and/or DSQL. While Python is a common language for working with data, not everyone knows Python. Missing from the current tools is something that offers simple-to-use, yet flexible ETL data pipeline creation opportunities in JavaScript.
Returning to Pharma Co, the company needed a tool that could extract and transform its data. The merging process is done relatively simply through code, but their development team specializes in JavaScript development and has extremely limited Python experience. Because they only need to create ETL data pipelines, so a tool that specializes in that type of workflow generation would be ideal for their needs.
Introducing Otto
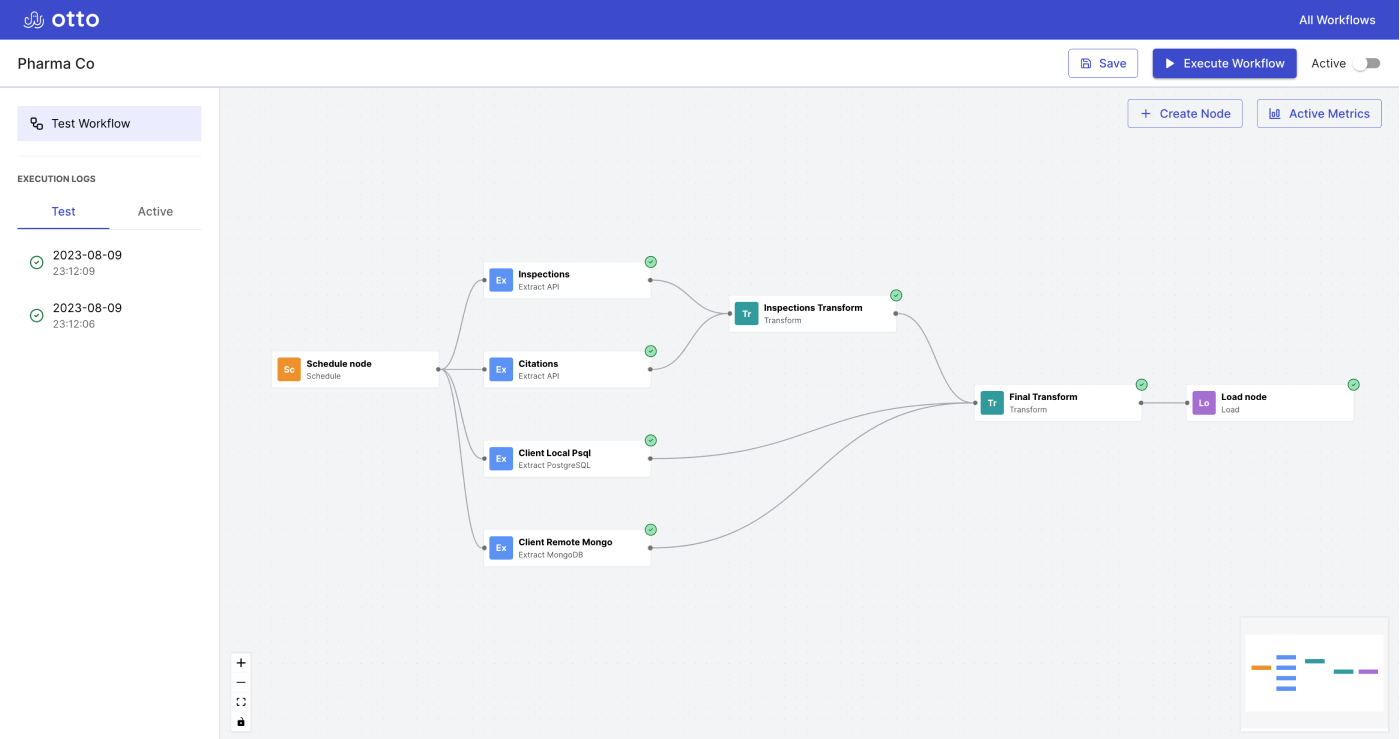
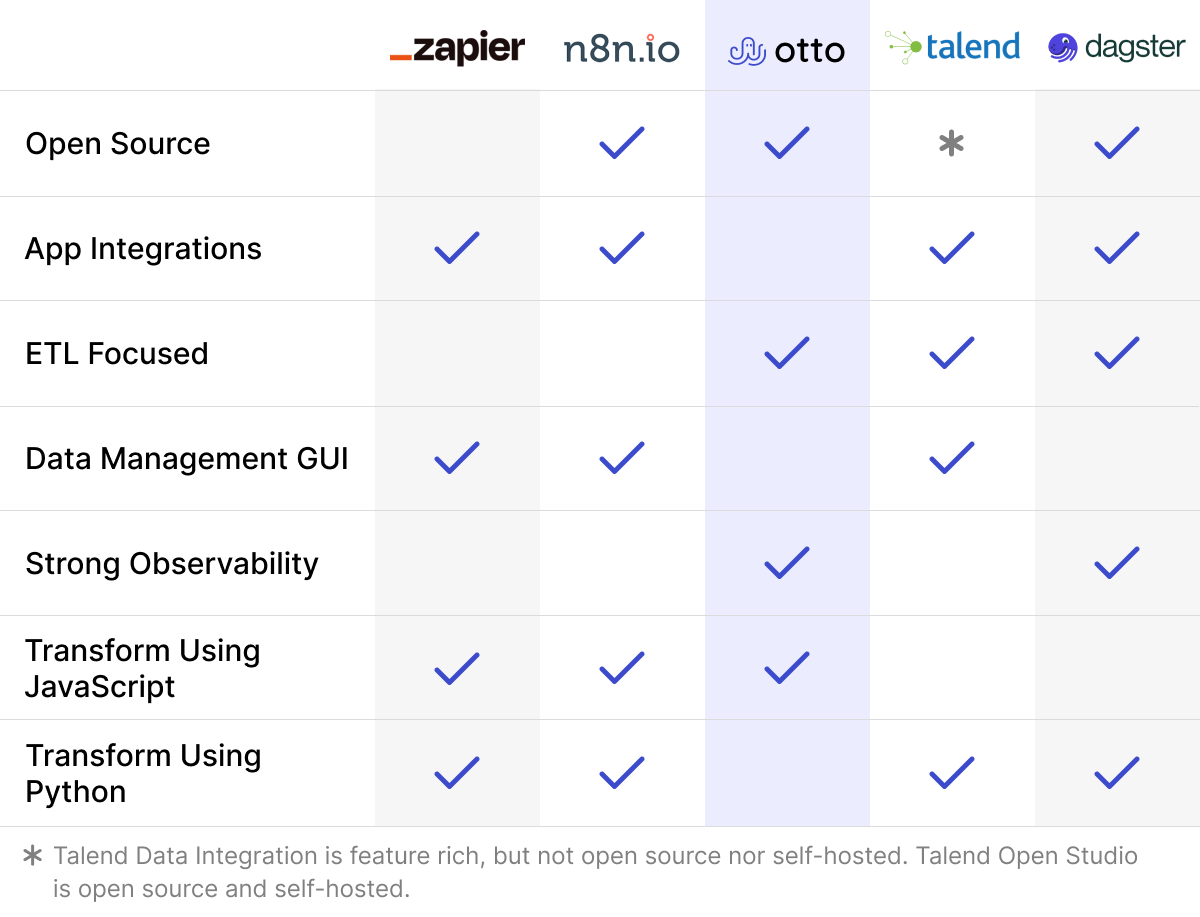
Otto is an ETL-focused workflow automation tool designed specifically for JavaScript developers that provides intuitive workflow-building tools and provides strong observability into both successful workflow executions and workflow errors. The tool supports developers who need to build automated ETL workflows from small- to medium-sized extraction sources: those that process up to 255 MB of data. This translates to about 200,000 rows in a 15-column relational database table. While the existing workflow automation tools cover a diverse spectrum of needs, no single tool provides all of these functions. We built Otto to fill this gap.
Otto was designed to cater to a specific set of users: those who wish to extract and work with data from APIs, Mongo databases, and PostgreSQL databases. Otto is not designed for users with needs not involving data extraction and processing, such as sending emails or posting to social media. Furthermore, workflow execution can only be triggered either manually or on a schedule; the tool does not support other types of triggers, such as webhooks. Finally, Otto is not for big-data processing or other workflows that must handle a large amount of data.
Prototype
Our first step in building Otto was to create a working prototype. For the prototype, we wanted the user to be able to work with an existing simple workflow that contained only a single copy of each node type: schedule, extract, transform, and load. We planned to only support manual workflow executions, but we wanted the user to be able to save and execute their changes to individual nodes. The ability to do this is critical to creating workflows because when doing so, you want to make sure that the changes you make to an individual node are functioning as you’d like. Changes to the workflow would have to be saved to a designated workflow database.

To create the prototype we envisioned, we had several hurdles to clear. Our prototype needed to:
- Execute, on manual command, a simple workflow as described above.
- Execute individual nodes in that workflow and string together the results of each execution to ultimately get the data to load to the final database.
- Extract nodes needed to connect to an external API.
- Transform nodes needed to execute arbitrary code against variable input data.
- Load nodes needed to connect to an external database and execuearbitrary commands in that database.
- Have a data structure that allowed the result of each node’s execution to be saved and to be referenced by the following node.
- Display the workflow to the user.
- This display needed to be interactive enough to allow the user to input new values into the nodes, e.g. entering code into the transform node.
- Save changes to node inputs to a designated workflow database.
Workflow Orchestration Engine
The sequential execution of nodes would be conducted by a workflow execution engine. As described above, a workflow orchestration engine schedules, executes, and monitors tasks in a workflow. The engine must ensure that these tasks are executed in sequence and that the correct actions are taken at each step in the workflow. Early in the process, we had to make a decision between building a custom engine from scratch or using a pre-built workflow engine like Dagster or Node-Red. We went with the custom engine so that we could cater the experience towards our design goals. We wanted to make sure the engine worked well with transforming data with JavaScript code. We also wanted the flexibility to choose how we represented data, tracked metrics, and handled errors.
While pre-built workflow engines like Dagster and Node-RED exist and would have allowed us to implement advanced features with the groundwork they already provide, we decided against that approach. These existing engines are robust and are designed to power the kind of flexible, code-heavy workflow automation tools after which we modeled Otto. While Dagster is ETL focused with strong observability, making it otherwise ideal, it is Python-based, and we set out to make a JavaScript tool. Other solutions were either not ETL specific, limited in their observability or error-handling ability, or poorly maintained.
We set up our workflow orchestration engine behind a client-facing API. Our original design assumed the existence of only four nodes: schedule, extract, transform, and load. Further, we did not build scheduling functionality into the prototype. Only manual executions were permitted. The client would send the most recent copy of the workflow to the orchestration engine. From there, the orchestration engine would update the workflow database with the most recent version of that workflow. Then, when the workflow is executed, the orchestration engine would validate the input data and begin the workflow execution algorithm. We will go into more depth about this algorithm below.
Architecture
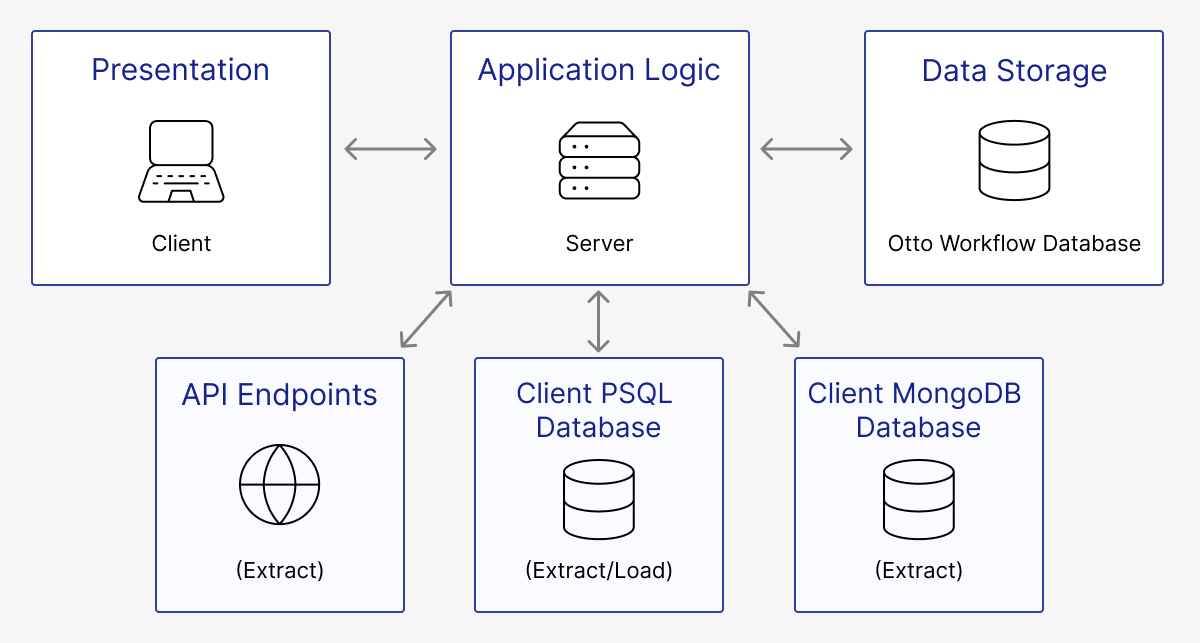
The initial Otto prototype was designed to use a three-tier architecture. Consequently, the application was divided into three separate layers: the presentation, application logic–home of the workflow orchestration engine–and data storage layers.
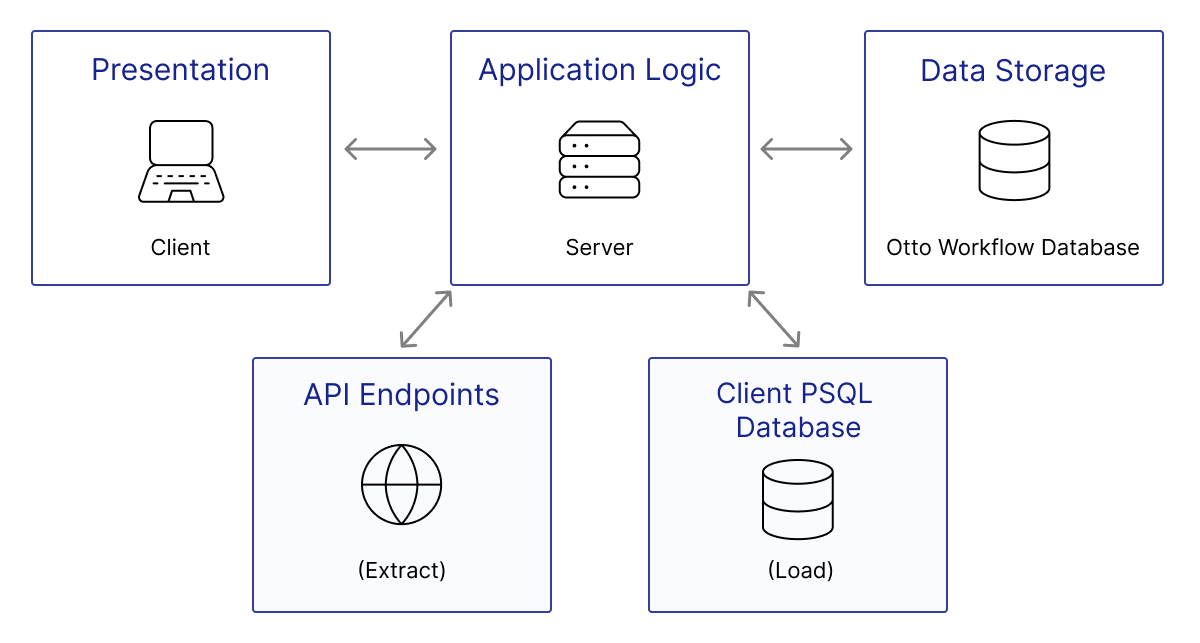
Each layer would be responsible for its own set of associated functionalities:
- Presentation
- Responsible for displaying the user interface, presenting information, receiving user inputs and handling user interactions.
- Application Logic
- Contains the business logic and core functionality of the application. It would process user inputs from the client, handle the workflow orchestration engine logic and handle the flow of information between the client and database.
- The server would also be responsible for making requests to API endpoints to facilitate data extraction, as well as, interfacing with remote or local PostgreSQL databases to load a workflow’s transformed data.
- Data Storage
- Responsible for managing the storage of workflow data within a local PostgreSQL database.
Frontend
Creating and Managing Workflow Visuals
One of our biggest UI challenges was creating the drag-and-drop node interface developers can use to create and manage their workflows. We wanted a 2D area for users to create, move, and connect nodes, with intuitive controls and a snappy feel. We also needed a way to manage the state of the workflow so node locations, connections, and existing input/output data would be remembered between sessions.
Setting up a drag-and-drop interface from scratch presented many challenges. To allow users to move nodes around and to zoom and pan around the space–basic features users would expect–we would need to do a considerable amount of behind-the-scenes math to repaint the screen in response to mouse input. There are more calculations involved in visually rendering edges, both as we drag to create them and as we move nodes around, requiring the paths to be repainted. And all of these calculations would need to be done quickly in order to prevent unnecessary re-rendering and provide a smooth, responsive experience.
React Flow
React Flow was designed specifically for use in workflow diagrams, with intuitive controls and robust state management out of the box. React Flow uses the Zustand state management library internally to keep track of data for nodes and the edges connecting them. This allows Otto to preserve workflow state across editing sessions. React Flow also handles all user interaction events and graphical calculations for its 2D grid. It does this while re-rendering the individual parts of a workflow diagram efficiently and quickly when they change.
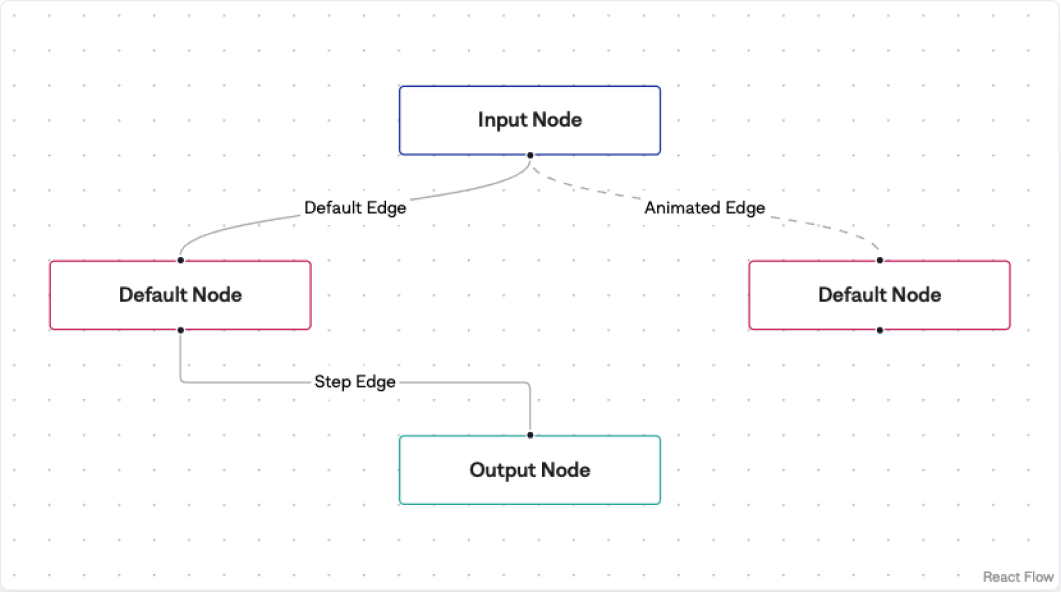
We considered alternatives to React Flow, but they had significant shortcomings. The React-Draggable library was simple and made it easy to implement basic drag-and-drop functionality, but since it is solely a 2D drag and drop library, we would have to implement everything else related to workflow diagrams from scratch. React DnD, while an otherwise excellent multi-purpose library for complex drag-and-drop interfaces, also would also require extensive implementation from scratch. Furthermore, it emphasizes decoupled components, which is often desirable, but for Otto we wanted our components coupled together in a single workflow object.
React Flow, although the best of the available options by far, had its own tradeoffs. The tool enforces a fairly rigid structure for nodes and edges. While this structure worked well for our needs, it could cause complications down the line if we wanted a more complex representation of workflow state. React Flow nodes contained predefined fields that described the node’s metadata. One of those fields, the data field, was reserved for additional app-dependent information that the node should carry. All of our Otto-specific details are stored in a node’s data field, and for React Flow to re-render workflows properly, there needed to be a finite cap on how deeply the objects inside were nested. However, since a node’s output data can theoretically be nested indeterminate levels deep, we needed to impose some limitation.
We chose to represent all output data as one JSON object in our application, which worked reasonably well since many APIs return JSON anyway but did impose some restrictions on what data types we could handle. Because React Flow handles its re-rendering and state management internally, we also had to defer to its logic in order for workflow updates to be displayed and persisted properly. The library provides hooks for this, but keeping React Flow’s state synced with our backend state often proved challenging.
Data Representation
Our initial representation of workflow data was simple, based on React Flow’s internal data structure. Nodes are stored in a nodes array, with objects containing a UUID to serve as a reference to the node, the node’s type (which React Flow maps to components), its x and y position in the workflow grid, and a data object that could hold user input and node execution output. Edge objects, stored in an edges array, track their current source and target node UUIDs.

Our prototype supported four node types (schedule, extract, transfer and load), each with its own specific set of data attributes. The schedule node, in this early prototype, was left as a placeholder–users would manually execute tasks. All other nodes had one input field in the UI that allowed the user to enter all input data as a string.
We had one subtype of extract nodes: API extract nodes. These took an API endpoint URL, HTTP verb, and JSON body as inputs; when executed, they sent a HTTP request to the API endpoint with those details and captured the returned data. Transform nodes allowed users to enter JavaScript code as input. This code had access to the output data from the preceding node in order to manipulate that data. The output of a transform node was the return value of that JavaScript code. Load nodes allowed users to enter database credentials, host name, port, and other specifications, as well as a SQL query. When executed, the load node connected to the given database to run the SQL code against the output data from the transform node.
Modeling and Storing Data
Another significant infrastructure decision was choosing the type of database in which our data would be stored.
At the prototype phase, we only needed to store workflow data. As mentioned in earlier sections, Otto targets workflows with small to medium extraction sources (up to 255 MB of data). Nodes and edges data needs to be queried and then formatted to arrays of objects in order to be consumed by React Flow. An active workflow would have 4 to 10 nodes on average and would be set to run at a frequency of once a day to a few times a month. The number of workflows each client has depends on their business needs; however we expect a typical client like Pharma Co to have no more than 20 active workflows. If we assume that when a workflow is executed, each node hits the database twice, once to retrieve data and once to save execution results we would need less than 500 queries per second (qps) even if a client runs all its workflows at the same time everyday.
Because one of our main goals was to build an ETL tool with robust observability, we knew that in our second phase of development we would need to add a way to store logs and metrics. The logs and metrics data need to be mapped to the corresponding workflow entity and our database solution needs to allow us to query these data easily.
Other additions that we planned to add were more integrations. For example, we would like to add other extract node types that allow users to extract from SQL or NoSQL databases. This adds uncertainty to the structure of individual node objects and our storage solution needs to be flexible to accommodate changes.
Storage capacity
The maximum BSON document size for MongoDB is 16 MB, and the maximum JSONB document size for PostgreSQL is 255 MB. This means that if we used MongoDB, we would soon run out of space if we stored a workflow’s nodes and edges data in a single document. Spreading them across multiple documents and/or storing nodes and edges data separately, however, would make it difficult to query a single workflow, as we would have to join these by workflow ID every time.
One of the advantages that some other NoSQL databases offer is substantial storage capacity. However, since Otto is a light ETL workflow automation tool that targets smaller workflows, storage capacity is not a major concern for us.
Query speed
A document database like MongoDB is capable of handling a larger number of qps than a relational database like PostgreSQL. Since Otto is a ETL-focused workflow automation tool that supports cron jobs as workflow triggers, we do not need to process as many queries per second as automation tools that use webhooks as triggers. SQL databases’ query speed is more than sufficient.
Observability considerations
As mentioned earlier, our observability data are relational to our workflow data. Even though some NoSQL databases like MongoDB support relational operations like joins or cascade deletes, this would require far more work than using an inherently relational database.
Column flexibility
A NoSQL option like MongoDB seemed promising, as we wanted to be flexible about what types of data nodes could receive and process. However, the JSONB data type in PostgreSQL also provided this flexibility–and since we were already restricting our output data to JSON, it made intuitive sense.
We ultimately chose to store our data in a PostgreSQL database and store our nodes and edges arrays in JSONB columns of a workflow PostgreSQL table. We could have created separate tables for nodes and edges, but we found that the JSONB option had several advantages:
- Easy to scale: Because supporting other node types is a future goal, storing nodes in a JSONB column prevents some schema changes in the future. Storing all nodes in one node table would also result in a substantial number of unused columns in the table, since not all nodes have the same fields. And creating a new table for each node type would soon result in an unwieldy number of tables that, again, would need continual modification the more types we add.
- Easy to query: Our server receives nodes’ data in JSON arrays and sends nodes’ data to our client in the same format. If we create separate tables for each node type, querying all the nodes in one workflow would require joining multiple tables. Using a JSONB column for nodes allows us to retrieve all the nodes directly.

A downside of storing nodes data in a JSONB column is that with this data structure, updating data for any given node requires us to search the entire nodes array for that node–a common operation that becomes exponentially more expensive for larger workflows. Querying aggregated nodes data also requires us to manually join the nodes data first. However, this seemed difficult to avoid without significant effort. One consequence of this decision was that Otto cannot handle more than 50 nodes in a single workflow without noticeable app lag.
Workflow Execution Algorithm - Part I
For our prototype, we wanted to support execution of simple workflows, and we assumed that no branching or “orphan nodes” (nodes not connected to a complete, valid workflow) were present. At this stage, users could manually execute a node individually or execute the entire workflow in order.
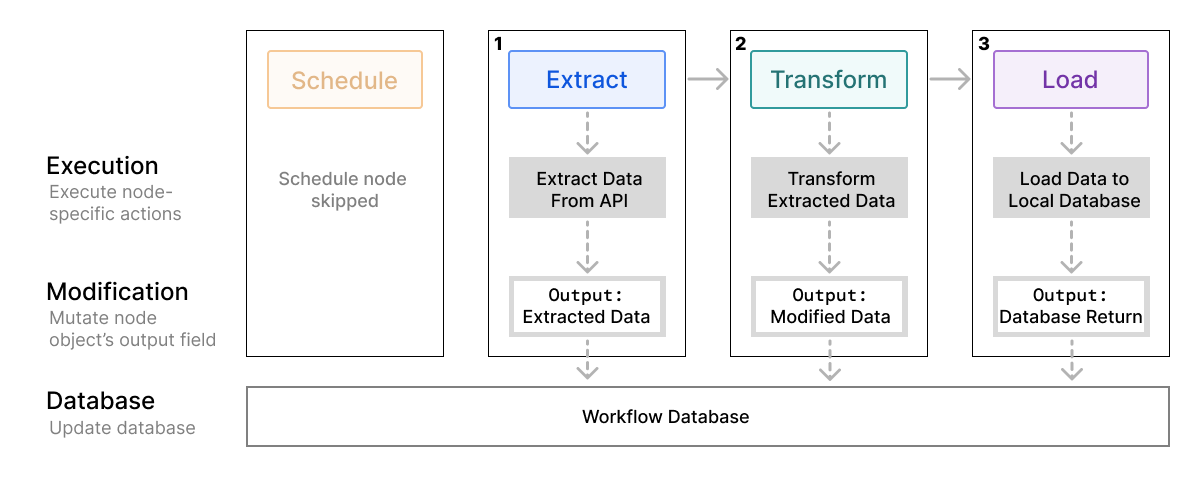
To support these two types of execution, we built execution functions for each node type. Each execution algorithm performs three high-level tasks:
- Executes a series of actions pertinent to a node type against the node object's data and the output data from the previous node. For example, for an extract node, this means sending an HTTP request to the user-provided API endpoint with the specified HTTP verb, headers, and body.
- Mutates the node object's
outputfield with the return value of the execution. (e.g. for an extract node, the return value of the execution would be the body of the http response) - Updates the database with the new data.
We then built a basic workflow execution function. Our initial, naive version assumes that a workflow is linear, with no branching–i.e., there is only one of each node type, and either one or zero edges on either side. First, it iterates through the nodes array, identifies the unique extract node, and sets that object as the current node. It then iterates through the edges array to find the edge object with the current node’s ID as its source, obtains the ID of that edge’s target node, and iterates through the nodes array again to find that node. The algorithm pushes the node to the execution array and continues until it has pushed the load node. Finally, it executes these nodes in sequence against their respective execution functions. For simple linear workflows, this algorithm sufficed.
Code Editing
Overview
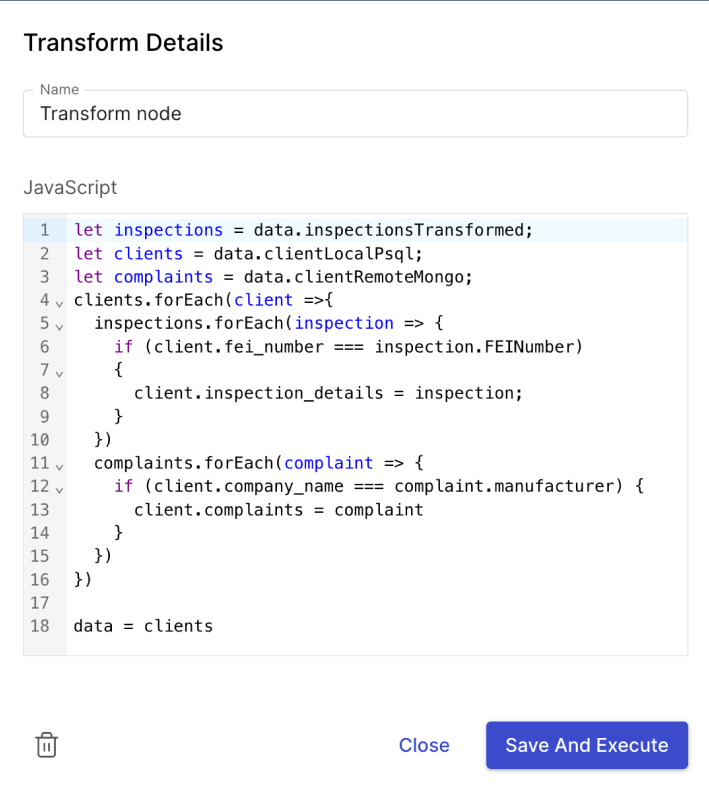
Another piece of core functionality in our prototype is code execution. There are several places along the workflow where arbitrary user inputted code has to be captured. The first location is at the data transformation step. After data is extracted from a source, it has to be transformed in some way. In Otto, that transformation is conducted via JavaScript code that the user provides. The other location is in the data loading step. Here, user supplied SQL is required to properly store the incoming data into the target database. The transformation step had an additional requirement. Otto’s workflow execution engine had to execute the code here against the incoming extraction data to transform that data. The two challenges that arose from these requirements were the process of capturing user code and then executing that user code against a given data set.
Several libraries exist to handle the capturing of user-supplied code without the inefficiencies, security risks, or subpar error handling that might arise if implementing one’s own. Developers also expect a code editor to include the quality-of-life features common in modern IDEs, such as syntax highlighting and autocomplete.
For Otto, we decided to use CodeMirror 6. The base package is minimal and allowed us to install only what we needed: a simple text-editor space for nodes. CodeMirror also offers syntax highlighting and some autocomplete functionality out of the box. Finally, it has excellent documentation and is easy to integrate into React.
Other code editors we considered include Cloud9 and Ace and Microsoft’s Monaco. These editors are more sophisticated but integrated less seamlessly into our code structure, and we found CodeMirror’s feature set more than sufficient.
Implementation
We had a way to capture user code, but we now needed to be able to execute it against incoming extraction data to transform that data. Once we added scheduling functionality, workflows would often be executed without the frontend being displayed. It would be preferable to execute the transformation code in the backend workflow orchestration engine so that unnecessary HTTP requests were avoided. The code execution also had to be able to interact with a given set of arbitrary data. The code had to be able to reference and transform that data in some way. Finally, the returned result of the data transformation or any resulting errors had to be captured by the process. Returned data had to be passed to the load node. Errors had to be captured and displayed in the logs we planned on implementing in the future.
We discussed several options for executing user code in the backend and chose the Node.js module node:vm5, which allows JavaScript code to be parsed and executed with a virtual machine running in Node’s V8 engine. The method vm.runInContext runs code inside the VM, and data may be passed into and mutated by it. The method will also return any error thrown while executing the code.
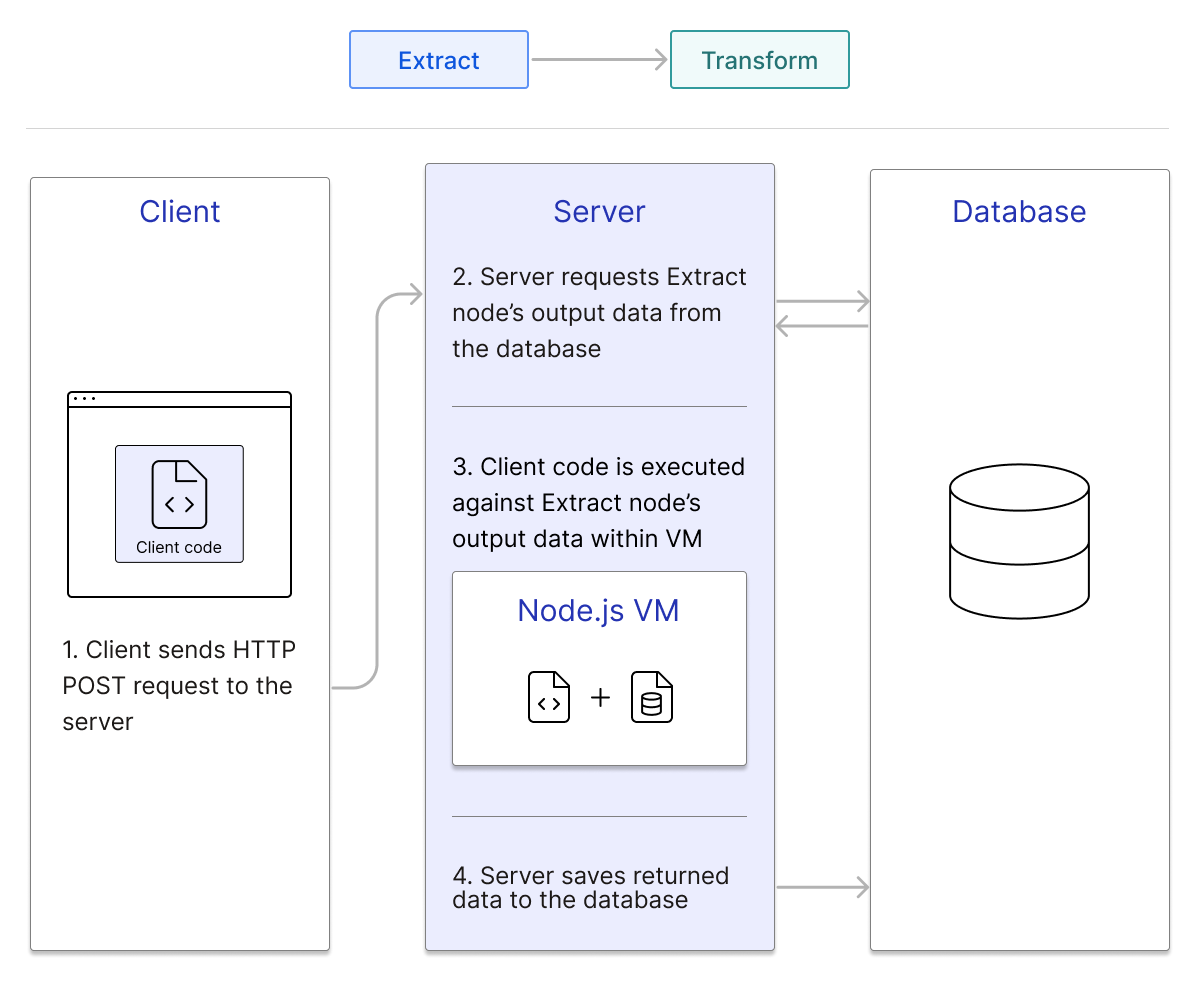
This method does come with some caveats. If a workflow has multiple transform nodes, a separate VM must be spun up for each one. The vm module also presents security risks if provided malicious code; however, because Otto is locally hosted, developers can be reasonably assured that their code can be trusted.
We considered other options for executing code, but their drawbacks were significant. The node-pty6 library emulates a code terminal, which would allow us to create a REPL as a Node.js child process. However, Otto only needs to execute code when a workflow is run, then spin down the execution environment when it’s complete. It does not need an environment that runs continuously. We also considered using the child_process.exec method to write users’ code to a temporary script file and then execute it. Passing external data to the child process is difficult, though, and Otto needs to do this every time code is executed.
Progress
At this point, we had successfully created a simple workflow editor and execution engine. We had a functional front end that displayed the existing workflow to the user. There, the workflow’s individual nodes could be attached and edited. A data source could be supplied to the extract node. Arbitrary code could be supplied to the transform and load nodes. In the backend, we had a prototypal workflow orchestration engine. Workflow edits from the frontend were saved to a dedicated database. Those workflows could be executed manually by the workflow orchestration engine. The orchestration engine could obtain data from an external API, transform that data with user-supplied code, and load that data to a local database.
Upgrading Core Functionality
Once we had a functioning prototype, we began fleshing out the Otto app and upgrading its core functionality. We aimed to:
- Improve the orchestration algorithm to handle branching workflow logic and scheduling, then turned our sights to enforcing node order.
- Streamline data transfer so that our workflows could handle a variety of incoming data formats.
- Add authentication validation to our extract nodes to improve the range of data sources our users could pull from.
- Implement our error handling and execution/metrics logging.
We will describe each of these below.
Workflow Orchestration Algorithm - Part II
Prototype limitations
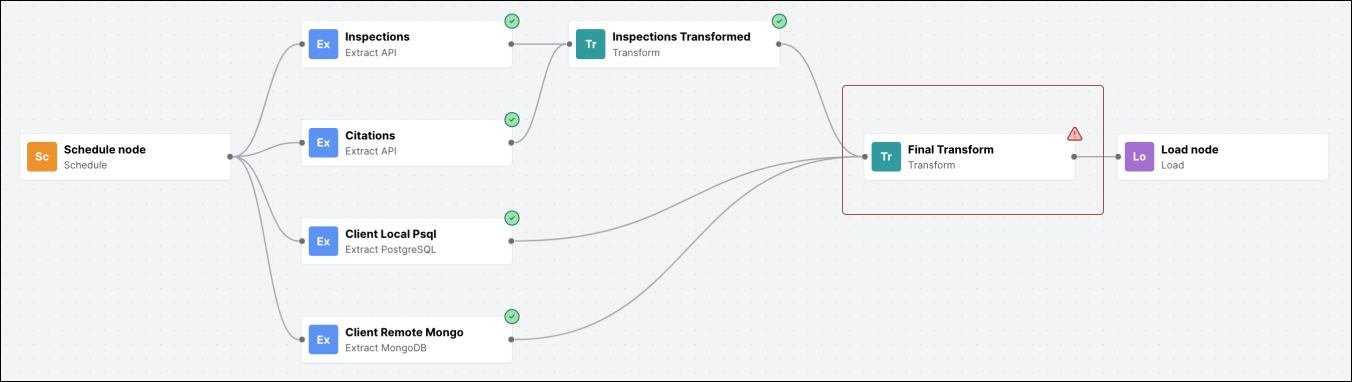
Our initial workflow orchestration algorithm handled data well for basic, linear jobs, but it severely limited users’ ability to create non-trivial workflows. A valuable piece of functionality for an ETL automation tool is the ability to execute workflows that branch out and/or merge back. For instance, two extract nodes might pull data from different APIs, and then a single transform node might transform the data from both. This was impossible with our current algorithm, which relied on node types and edge sources and targets being unique.
Branching workflows also created a significant dependency challenge. When a workflow branches out, each branch should be able to execute concurrently when it has all the data that it needs to function. When a workflow merges, the target node needs to wait for all its incoming nodes to finish before it can begin execution. We needed a pathfinding algorithm to traverse our graph of nodes and edges, find a possible order of execution, and ensure that no nodes start running before they receive their data and that no nodes delay running when they already have all the data they need to go.
Branch out and merge back
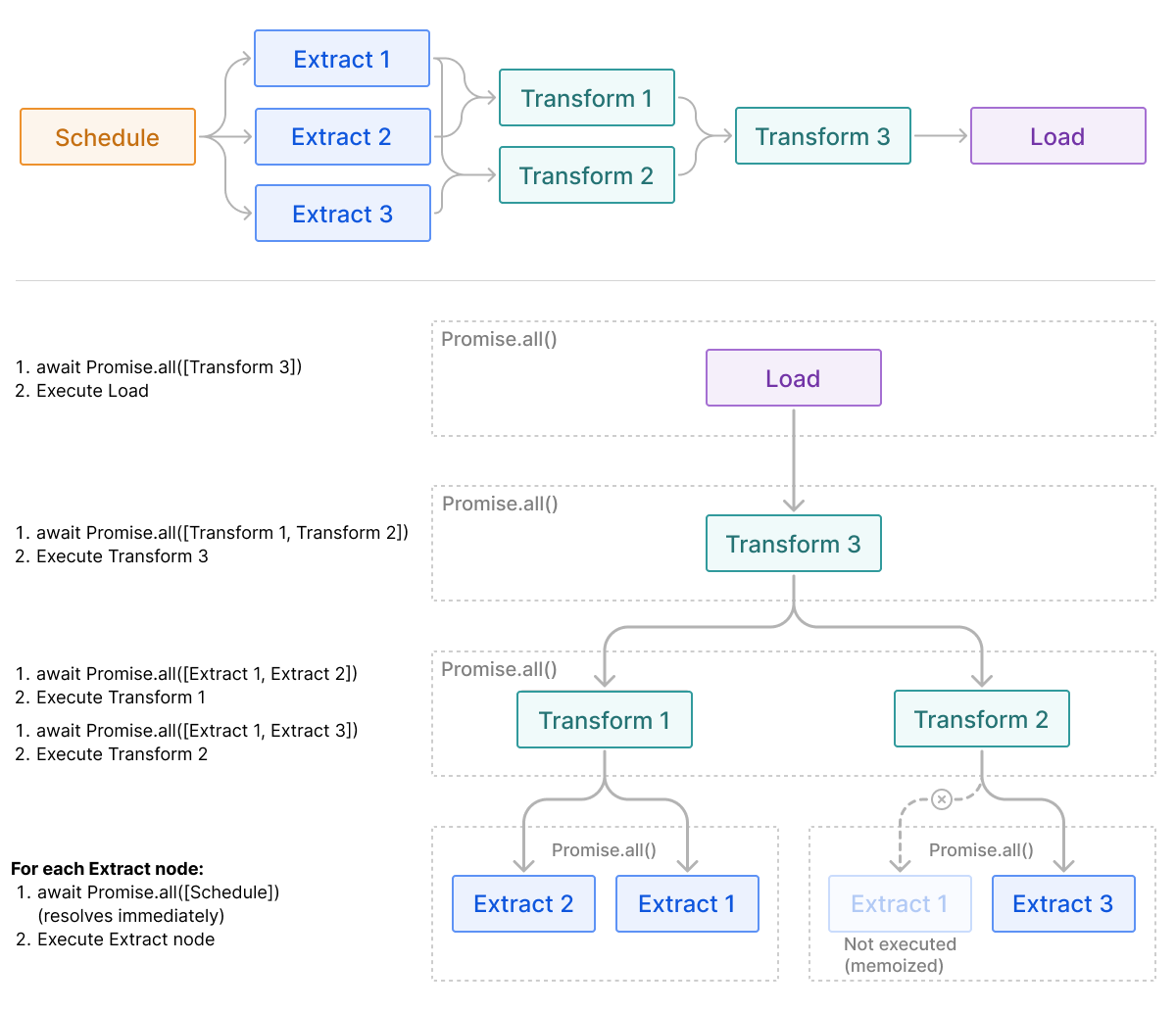
To solve this problem, we created a recursive algorithm. A function, runWorkflow, is called on every load node, and does the following:
- For a given node, the function looks for all the previous edges that have the current node as their target, finds the node connected to the source side of that edge.
- The function calls itself recursively against each of these source nodes. Each recursive call is wrapped inside a
Promise.allinvocation, allowing for asynchronous, concurrent execution of branches. - When the
Promise.allcall for a given node resolves, this indicates that the node has all the data that it needs to run. - A function returns when there are no incoming edges.
We later memoized the Promises created for a node ID in this function to ensure that nodes were not executed repeatedly if they appeared in multiple branches. If a node ID has an existing promise in the memoization table, we wait for that Promise to resolve (if it’s settled, then it resolves immediately) instead of unnecessarily re-executing the node.
Scheduling
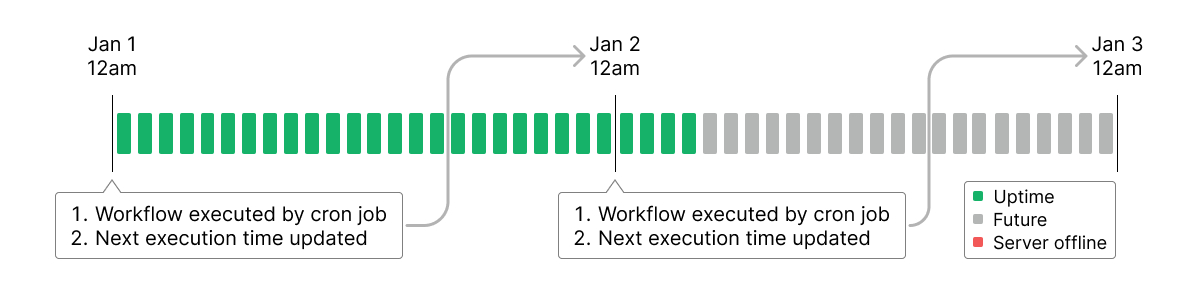
In our prototype, the only way to execute the workflow was for the user to manually click “Execute.” In order to support automatic recurring executions, we used the node-cron library to create cron jobs. Once the user specifies a start time for automatic execution and an interval between executions, Otto will schedule a cron job for that time and re-execute the workflow on schedule.
One limitation of this scheduling system is that when the server restarts, any currently running cron jobs are lost. So we refined the implementation as follows:
- Whenever a cron job is executed, we update the database with when the next execution should occur.
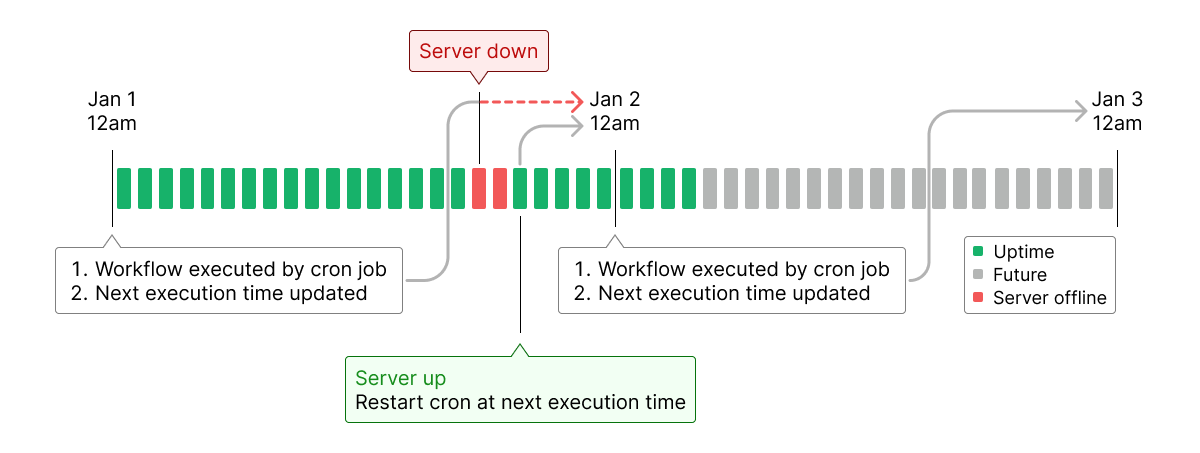
- If the server restarts before the next execution time, our application automatically checks for all currently active workflows and schedules new cron jobs at their respective start times.
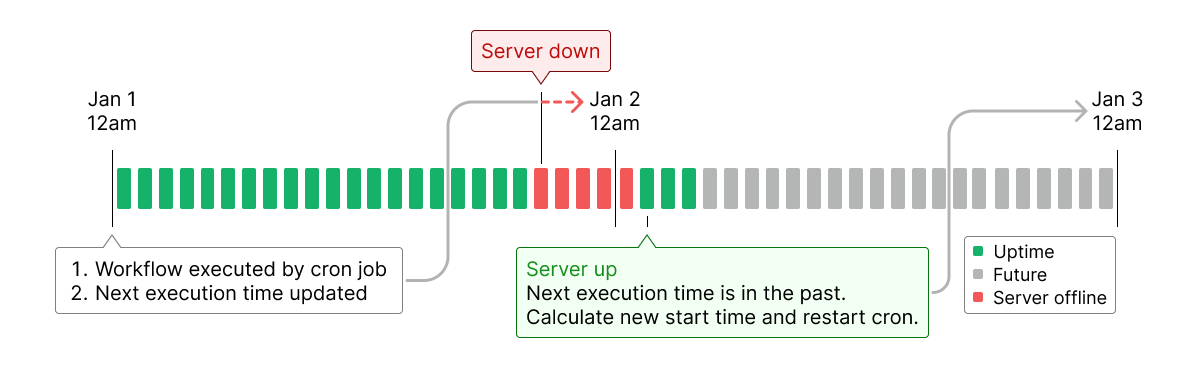
- If the server has been down long enough that a workflow’s next scheduled execution time has already passed, we calculate the next appropriate start time according to the interval and reschedule cron jobs accordingly.
Workflow Validation
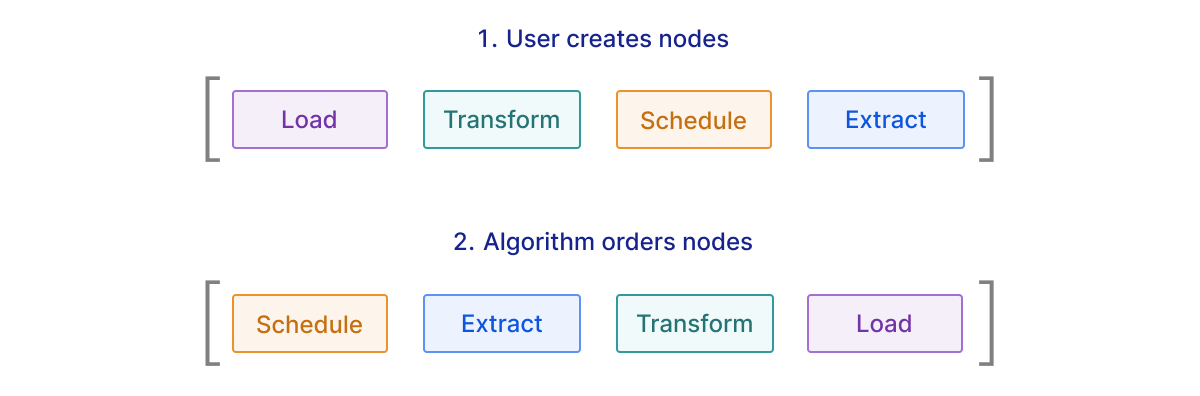
Enforcing Node Order

Otto enforces what nodes can be connected to other nodes
The steps in an ETL workflow must be executed in sequence; for instance, you cannot transform data you haven’t extracted. Human error, however, is common, and React Flow does not provide any restrictions by default as to which codes can be connected. With its base functionality, users could easily create unhelpful or impossible workflows, with no indication that they are invalid until the workflow fails on execution.
We implemented a ruleset to ensure that users’ workflows go through the ETL steps in a meaningful order. Schedule nodes may only connect to Extract nodes and cannot have incoming connections. Extract nodes may only connect to Transform nodes. Transform nodes may connect to other Transform nodes, if a user wishes to chain data transformations, or to Load nodes once the transformation is done. The Load node, as the final step in the process, cannot have outgoing connections.
We found this to be the best solution by far. It simplified our code significantly, as we no longer had to add checks at every node to validate its connections. Implementation was also straightforward; React Flow has built-in hooks for users to implement logic upon attaching, detaching, or deleting edges, and it restricts edge connections to pre-defined endpoints (called handlers). Most ETL workflows are possible under these restrictions. We plan to implement more granular logic in the future to make more complex workflows possible and to anticipate invalid edge cases, such as circular workflows.
Data Processing
Automating an ETL workflow presents several challenges in processing the information that flows through it. Different databases or APIs will likely return data in different formats and/or schemas. Since most non-trivial ETL workflows will extract data from multiple databases, we needed a way to funnel those multiple sources of information into one data object in line with the schema of the developer’s final database.
Otto does this by storing all data that a node outputs into a data JSON object, which is made available to subsequent nodes and the code inside them. For instance, the data from an Extract node called “pharma” is accessible within a connecting Transform node in the object data.pharma. This acts as a container; while the contents of this object may be different – for instance, JSON received from an API endpoint versus the results of a SQL query – the outer data structure remains the same.
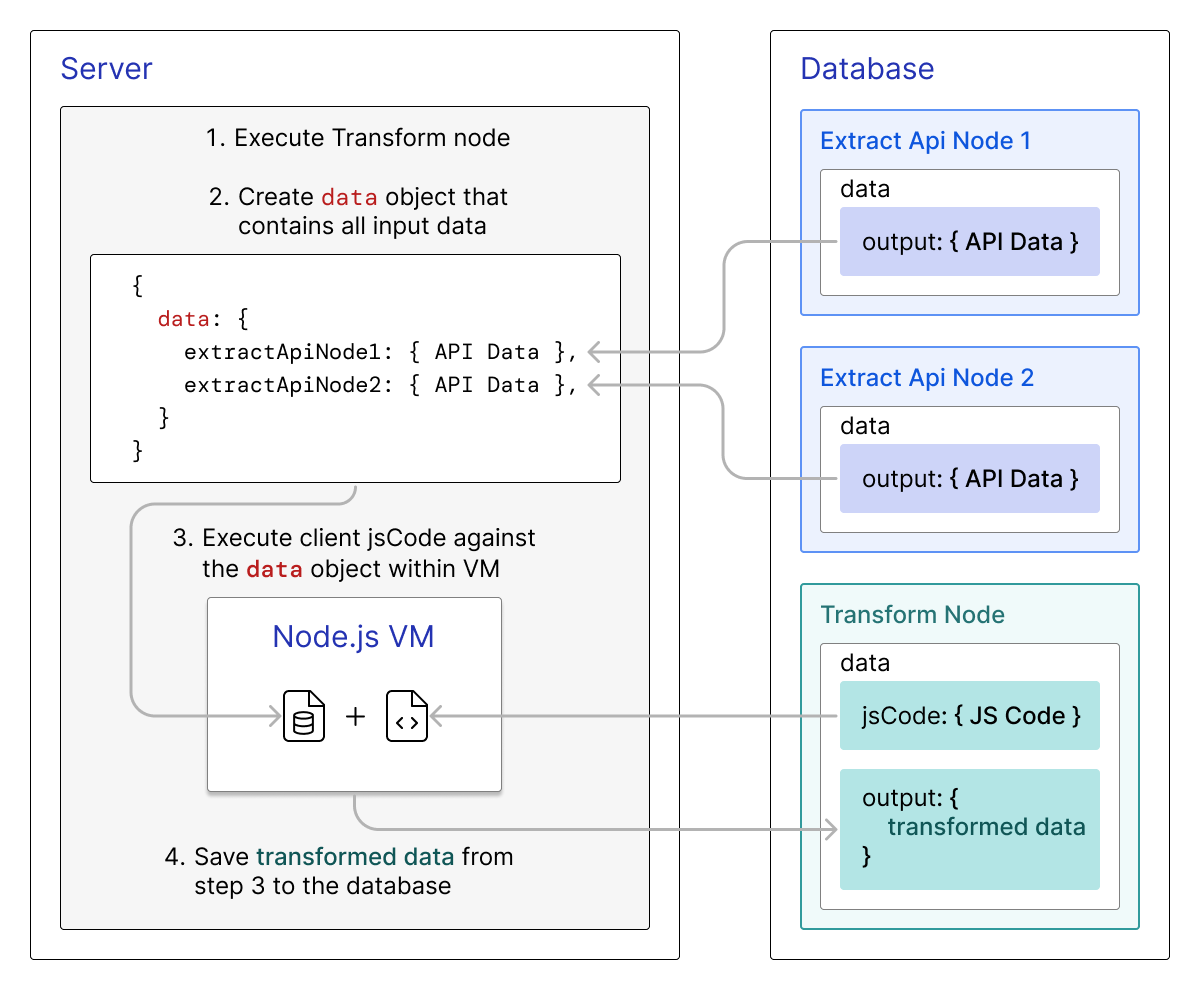
Node output is stored within a data JSON object that is made available to subsequent nodes
This is what makes more complex branching workflows possible. Our original version of Otto allowed for only one data object from a single Extract node, rather than multiple; furthermore, Transform nodes would output a different data structure, making it impossible to chain multiple transformations. Standardizing the data structure meant that nodes no longer needed to know anything about where the incoming data came from or what the previous nodes did with it; they became encapsulated, standalone entities.
Component Library
Our frontend app was growing increasingly complex. We needed more sophisticated UI elements compared to our prototype, such as styled input fields for all modals, date input fields for the schedule node modal, and tabs to separate test and active execution logs. These are common enough elements that the major React component libraries have many solid, accessible versions available. We considered Material UI7, React Bootstrap8, and Ant Design9.
Of these, React Bootstrap would let us work quickly after we got started, but the framework is rather standardized, with fewer options for customization. Ant Design offers many enterprise-level components and internationalization tools, which were lesser priorities for our prototype app. Material UI proved the best fit. We were already familiar with it, saving us a great deal of time, and it has great documentation that we knew our way around. It offers a slim installation package, allowing us to style and work with just the components we wanted to use, and accessible built-in styling with subtle animations and good UX design. The main trade-off of Material UI is that we spent additional time configuring the look and feel of certain UI components, time that might have been saved if we opted for vanilla React.
API Extraction Validation
Many APIs require authentication to prove that users are authorized to access the data they request. Because this is so prevalent, we needed some way to allow users to provide credentials for an API endpoint in the app’s interface.
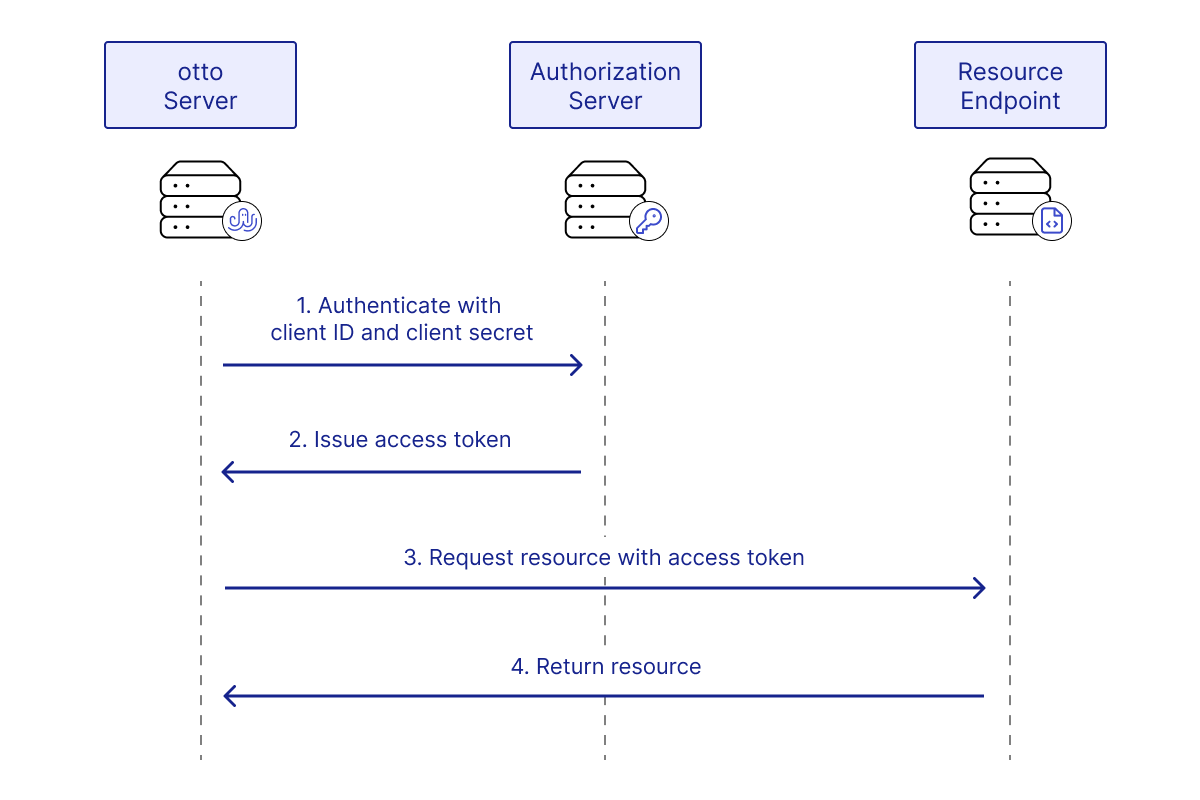
There are many ways to do this, but we chose the two authentication methods we believed to be the most broadly useful: request headers and OAuth 2.0. Among all OAuth 2.0 grant types, authorization code and client credentials are the most widely used.
The Authorization Code grant type10 is used by confidential and public clients to exchange an authorization code for an access token. After the user returns to the client via the redirect URL, the application will get the authorization code from the URL and use it to request an access token.
The Client Credentials grant type11 is used by clients to obtain an access token outside of the context of a user. This is typically used by clients to access resources about themselves rather than to access a user's resources.
After consideration, we decided to support the Client Credentials grant type since our app would be requesting resources through an API without the presence of a user.
To Observability and Beyond
Logging
Now that workflows could run without direct user input, we wanted to give users a way to see what happened when they were away. In our prototype, users had no way to view logs of past executions. There was no data on how the past workflow performed, whether it was successfully executed or failed. When the workflow was triggered by a cron job, there was no indication that it was executed other than the server logs. In order to have better visibility on past workflow executions, we decided to add logging functionality to our app.
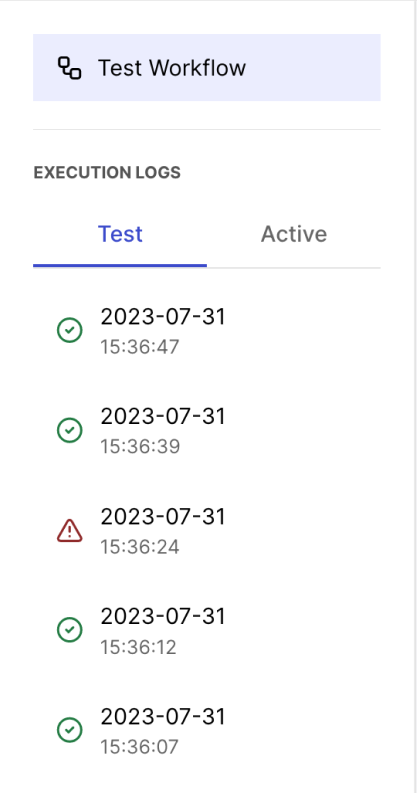
We first created an execution table in our database that stores data about past executions in a JSONB column. Inside is a workflow object with nodes and edges arrays that contain user input data for each node at the time of execution, the returned data and/or error(s) from the execution, and how the nodes were connected. Sending these data to the client allows the client to display an exact recreation of the state of the workflow at the time of execution.

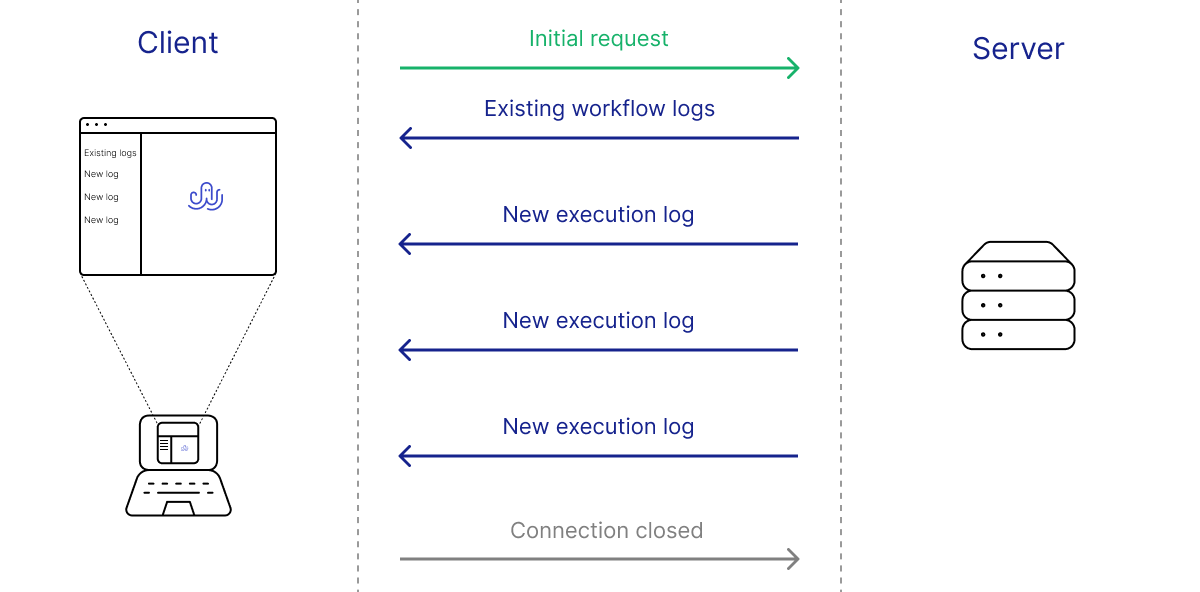
We then had to decide on how to communicate these data to the client. We want our user to be able to view logs of the workflow immediately after the workflow was executed, even when the execution was done via cron job. We considered three options: WebSockets, server-sent events, and client-side polling. WebSocket is a computer communications protocol that provides two way communication over a single long-lived TCP connection. Server-sent events is a server push technology that enables a server to send automatic updates to a client over HTTP after an initial client connection is established. Client-side polling involves the client sending regular requests to the server at predefined intervals to query for new data. We chose server-sent events because:
- Data transaction for logs is unidirectional (server to client only), and we don't send binary data, so WebSocket’s support for these would be unnecessary.
- Client-side polling would create unnecessary requests to the server when nothing is happening.
Error Handling
When users build a workflow, they inevitably make mistakes. These include entering the wrong URL for an API endpoint, providing the wrong connection credentials for a database, or syntax errors in their Javascript or SQL code. It is important for us to display the errors to the users in a human readable way to help them debug their own workflows. In order to do so, we catch errors at each step of the workflow execution, throw custom errors with descriptive error messages accordingly and save them to the database. In our frontend app, these errors are displayed to the user as soon as the execution finishes at exactly where the error occurred (e.g. a Javascript syntax error from the Transform node shows up in the transform node)
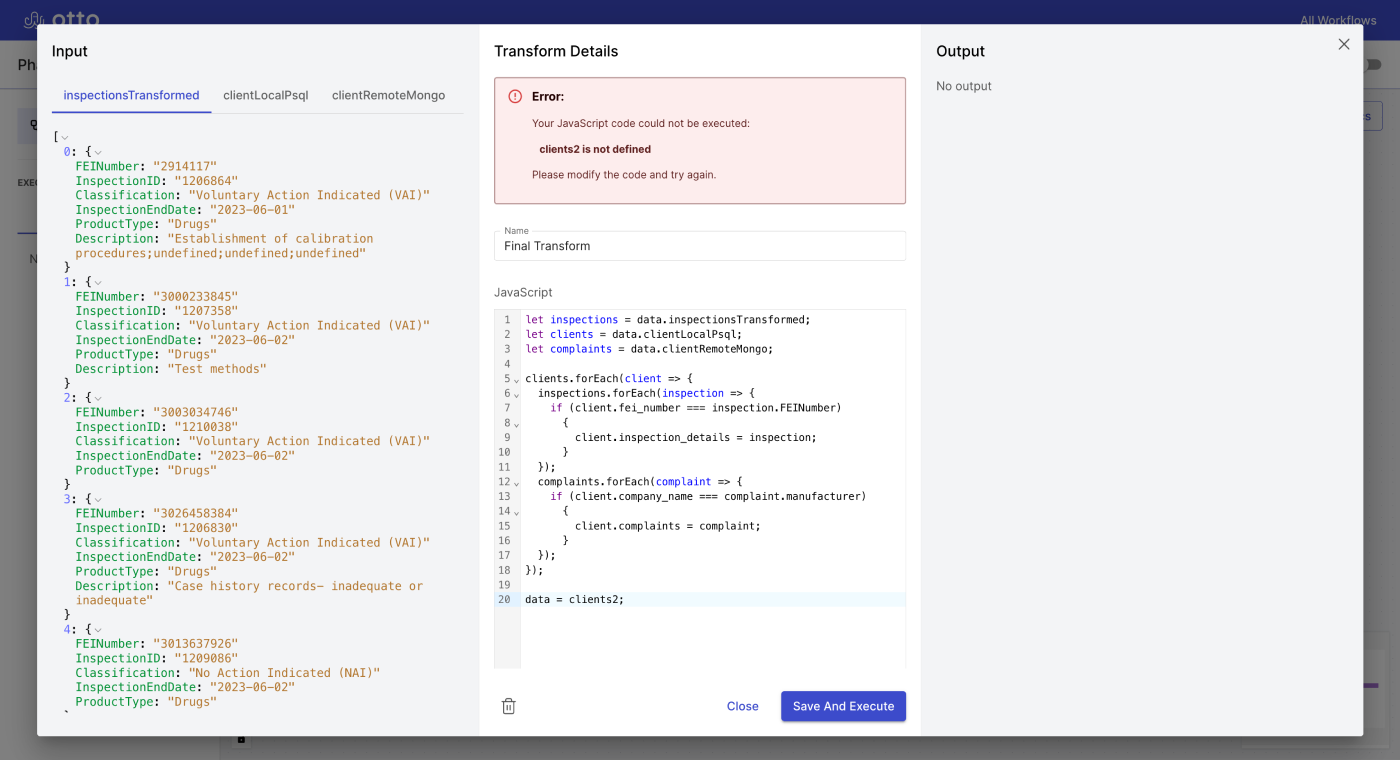
Other errors might occur while a cron job is active, such as a temporary issue with the internet connection when fetching API or the remote database server is down. We classify these types of errors as external errors. When an external error happens, our app will re-execute the workflow first after 1 second, again after 10 seconds, and once more after 100 seconds. This protects our workflow executions from short-term issues but avoids unnecessary retries during longer-term outages.
Metrics
Closely related to logging is keeping track of metrics about a workflow’s performance. Developers who frequently run workflows benefit from being able to diagnose issues and find improvements. For example, a user might notice that some transformation code is unusually slow, creating a bottleneck in the workflow. Or an API might be prone to failure, causing frequent but inconsistent errors at its corresponding extract node. For Otto, we chose a set of metrics that we thought would be useful for developers while not adding unneeded complexity to our workflow orchestration.
We track two kinds of metrics: metrics for an entire workflow, and metrics for individual nodes. Metrics are only tracked for active workflows. At the workflow level, we track the number of times a workflow has been executed successfully, the average time it takes for an execution to run. At the node level, we track the average time the node takes to complete, the average amount of data processed by that node, and the number of failures. Whenever a workflow is activated, its metrics are reset; this ensures that developers are not confused by out-of-date statistics.
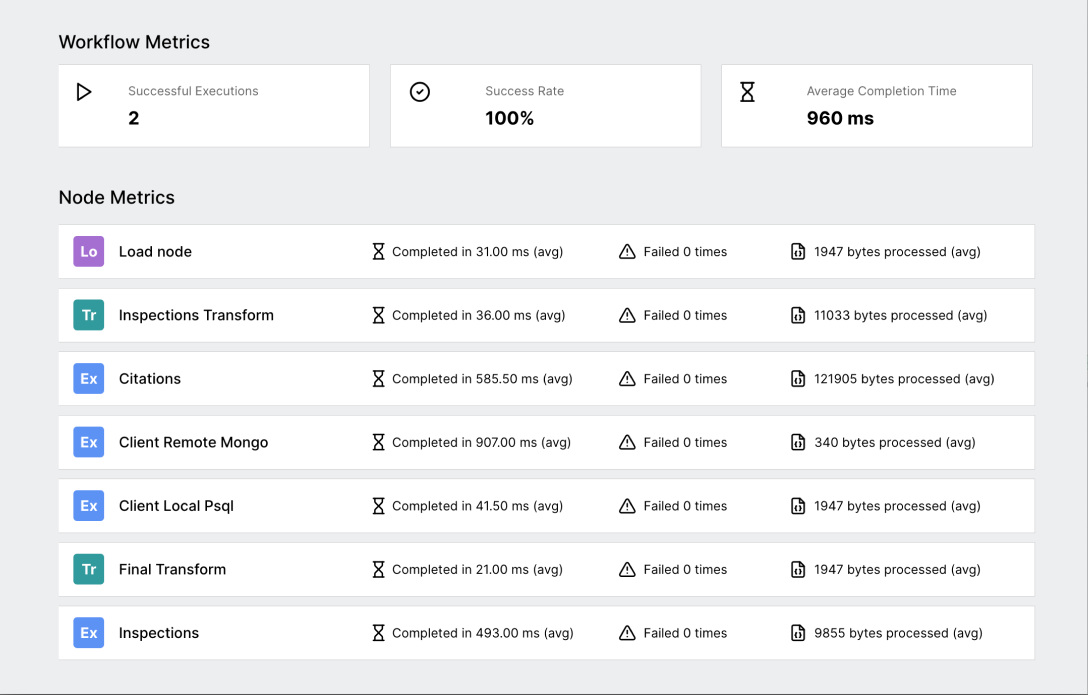
When a new workflow is created, a new entry is inserted into the metric table, with that workflow’s ID as a foreign key. This entry is instantiated with total executions set to 0, success rate and average execution time set to -1 as a placeholder, and empty JSONB objects to contain all node-specific metrics. These objects also contain a count of total executions, for calculating averages. When a workflow is activated, any existing entry for that workflow ID in the metric table is deleted, and a new entry is instantiated with initial values. This ensures that there is always only one metrics entry in our database per workflow. Since all metrics are displayed in the same modal, the frontend queries this data as a whole.
At the workflow level, the start time is taken at the beginning of a workflow’s execution in the backend. Should the workflow successfully execute, the time elapsed from start to end is measured, the average execution time for that workflow is recalculated and the total executions incremented, and the database is updated.
At the node level, the start time is measured immediately before executeNode is called. Assuming the execution was successful, once executeNode returns, that node’s metrics are updated. The total time elapsed is recalculated as above, and the average volume of extracted data is calculated based on the length of the JSON object returned from the node. Since Otto wraps all output data as JSON, this seemed like the most straightforward way to estimate data volume.
If a node fails, then the entry in the node_failure_count JSONB object corresponding to that node ID is updated to increment the total failures. If there is no corresponding entry in the node_failure_count object, one is created.

The Final Product
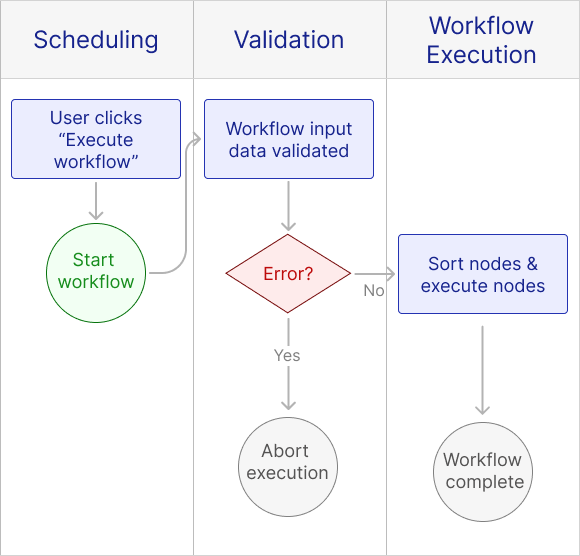
After implementing metrics, our fundamental workflow orchestration system was complete. Upon starting the workflow execution, the input data is validated. Following validation, our recursive function executes each node of the workflow in turn. Upon workflow completion, metrics are recorded and inserted into the database, along with a full log of the execution. If an error is thrown at any point in the process, the workflow’s execution stops and the metrics and execution log data are saved. If that error is an external error, Otto attempts to retry the execution; if it is an internal error, no retries happen.
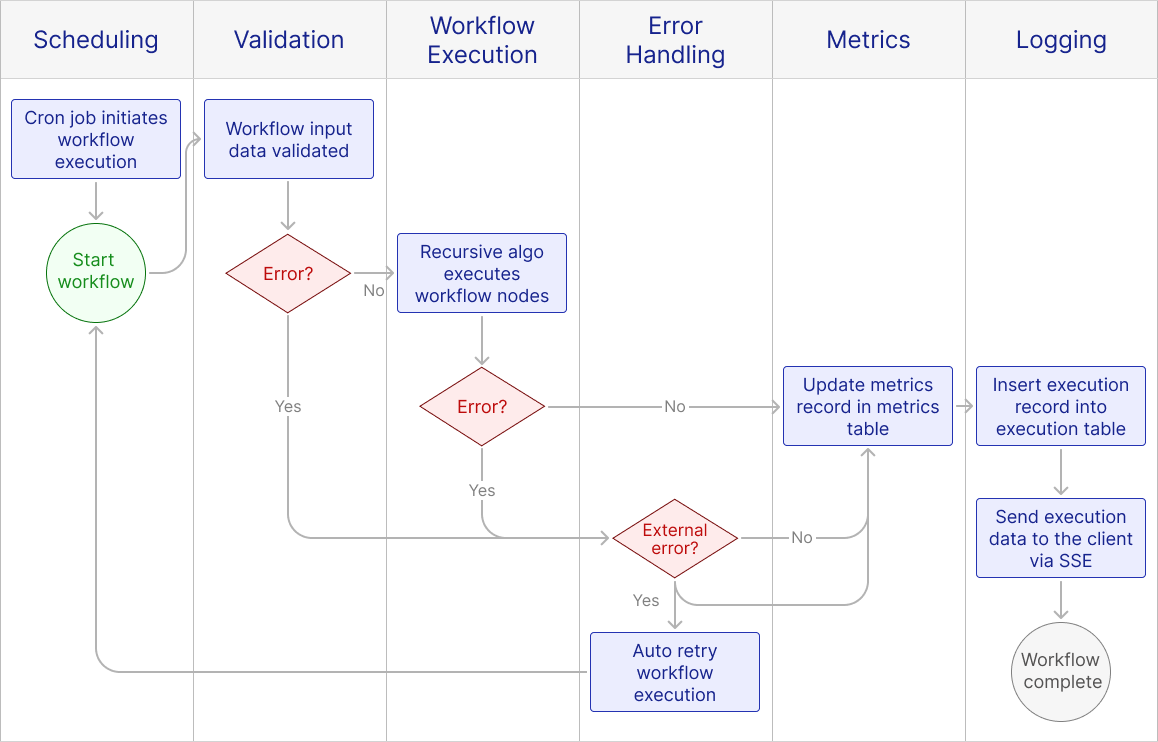
Between our prototype and our final product, our architecture didn’t undergo many changes. The only notable changes were the addition of two potential sources of data extraction. In addition to APIs, we could now pull from Mongo databases and PostgreSQL databases. Additionally, we expanded our workflow database to include tables for execution logs and metrics.
Future Work
To take Otto to the next level, we plan to offer many more features, such as:
Additional Integrations
While Otto's built-in integrations are currently limited, our data structure is flexible, and our code is reusable, which allows us to add additional integrations with minimal changes to the existing code base. We plan on adding Python transformation code, as Python is exceedingly common for data processing and analysis. We also plan to add node types that can interact with databases other than PostgreSQL or MongoDB.
More Capacity
Right now the amount of data that Otto can handle is constrained by the size limit of a PostgreSQL JSONB column: 255 MB. We are also limited in how much of this output our frontend can display to the user. As a light ETL workflow automation tool, this is not a concern. But if we want to serve users who work with larger data, we plan to investigate data storage solutions such as AWS’s S3. When we do this, each node’s output field will contain an identifier linking to the S3 bucket.
We also plan to optimize our extraction methods to allow users to handle more data. There are two types of data extraction: full extraction, which pulls all of the data, and incremental extraction, which extracts only a subset of that data in sequence. Users of Otto can do this manually by writing database queries, but in the future we plan to build these different methods into our extract nodes.
Cloud hosting
Otto is currently only self-hosted. We would also like to host Otto on the cloud. This would require us to add user authentication functionalities and additional security for executing client code. We would also need to upgrade to HTTPS protocol to protect our data when they are transferred over the internet.
Additional layer of abstraction
Otto's current target users are developers who are comfortable with writing code. To expand our user base, we would like to add features that abstract away coding and allow less technical users (e.g., the analyst from Pharma Co.) to use the tool as well.
References
- https://hbr.org/2016/09/bad-data-costs-the-u-s-3-trillion-per-year
- https://n8n.io
- https://retool.com
- https://www.talend.com
- https://nodejs.org/api/vm.html
- https://www.npmjs.com/package/node-pty
- https://mui.com
- https://react-bootstrap.netlify.app
- https://ant.design
- https://oauth.net/2/grant-types/authorization-code
- https://oauth.net/2/grant-types/client-credentials